Abstract
ReWiND enables sample-efficient adaptation to new tasks by training a language-conditioned reward model and policy from a small set of demonstrations to learn new tasks without additional per-task demonstrations. We beat baselines by 2X in simulation and improve real-world pre-trained policies by 5X in just 1 hour.

We pre-train a policy and reward model from a small set of language-labeled demos. Then, we solve unseen task variations via language-guided RL—without additional demos.
Summary
Our core contribution is in designing ReWiND's reward model to capture three key properties: dense feedback, generalization, and robustness. See our paper to learn about how we achieve these properties!
Method
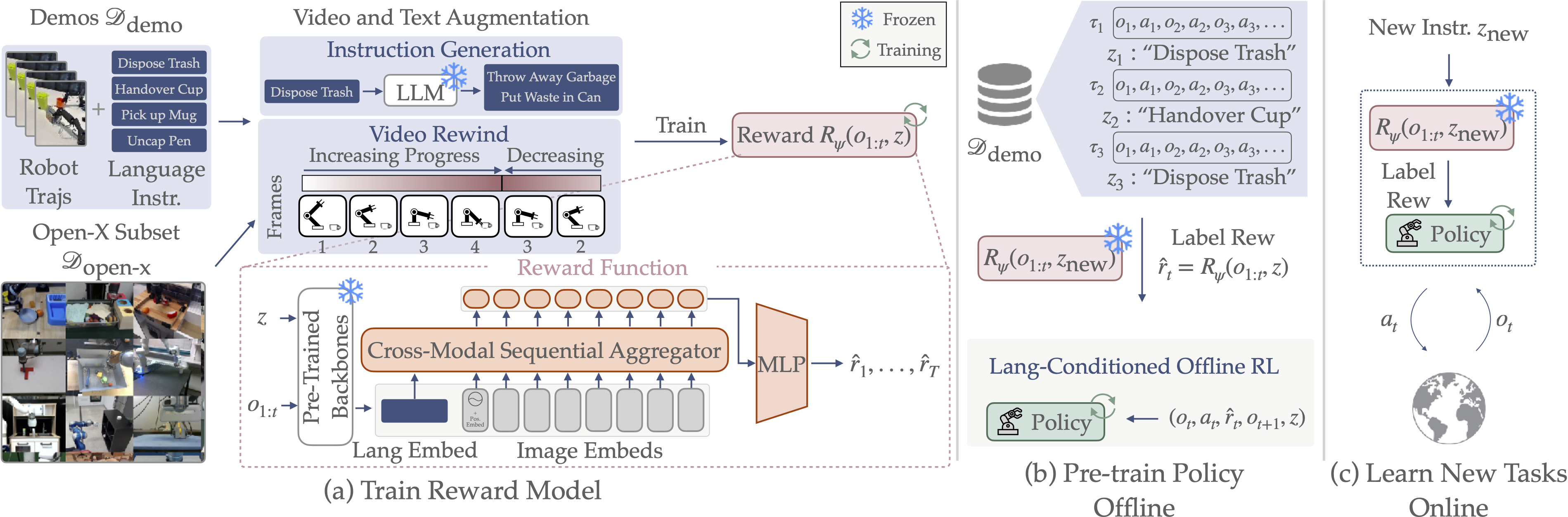
ReWiND is a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Our training pipeline consists of three main components:
Reward model training. We train a reward model on a small demonstration dataset and a curated subset of Open-X, augmented with LLM-generated instructions and video rewinding. The reward model predicts video progress dense rewards from pre-trained embeddings of each image or a video rollout and language instructions, and assigns 0 progress to misaligned video-language pairs.
Offline dataset relabeling & pre-training. We use the trained reward model to label the offline dataset with rewards and pre-train a language-conditioned policy using offline RL (IQL).
Online policy training. For an unseen task, we fine-tune the policy with online rollouts and reward labels from the reward model.
Video Rewinding
We split a video into forward and reverse sections to generate failure trajectories and decreasing progress from only successful demonstrations, allowing ReWiND to provide dense reward feedback even when the policy is making mistakes. Check out our ablations in the paper for more details, but video rewinding improves policy rollout rankings when comparing estimated rewards for successful, near-successful, and failure trajectories.
Environments & Results


(a) MetaWorld: MetaWorld provides large set of tabletop manipulation tasks in simulation.
(b) Real World Bimanual Manipulation: We also evaluate ReWiND on a real-world, low-cost, bimanual manipulation platform.
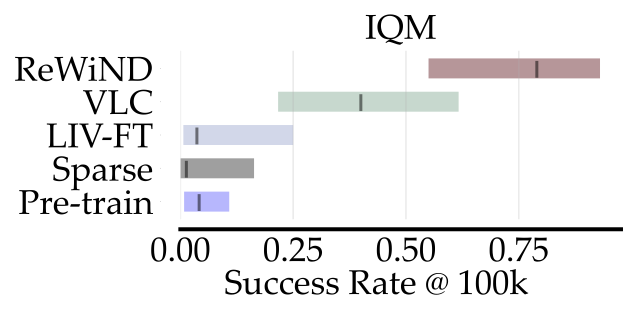
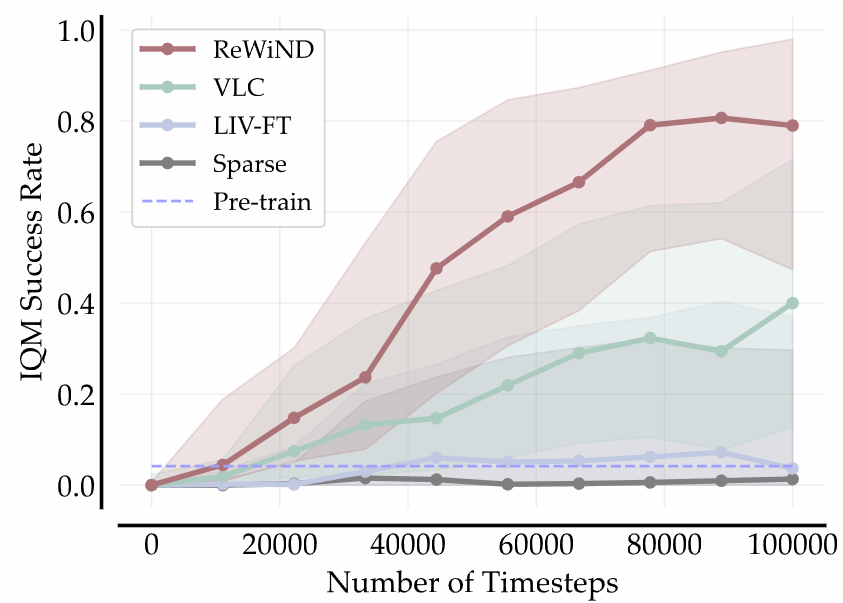
Meta-World RL Results
ReWiND achieves 79% success rate after 100k environment steps on 8 unseen tasks in Meta-World, 2x better than the best baseline. It is also more sample efficient than all baselines.
Real World Manipulation
Online Finetuning
We perform 5 seen and unseen tasks on table top bimanual manipulation with online finetuning with ReWiND rewards. ReWiND rewards enable learning unseen tasks and achieve high success rates in only 1 hour of online interactions.
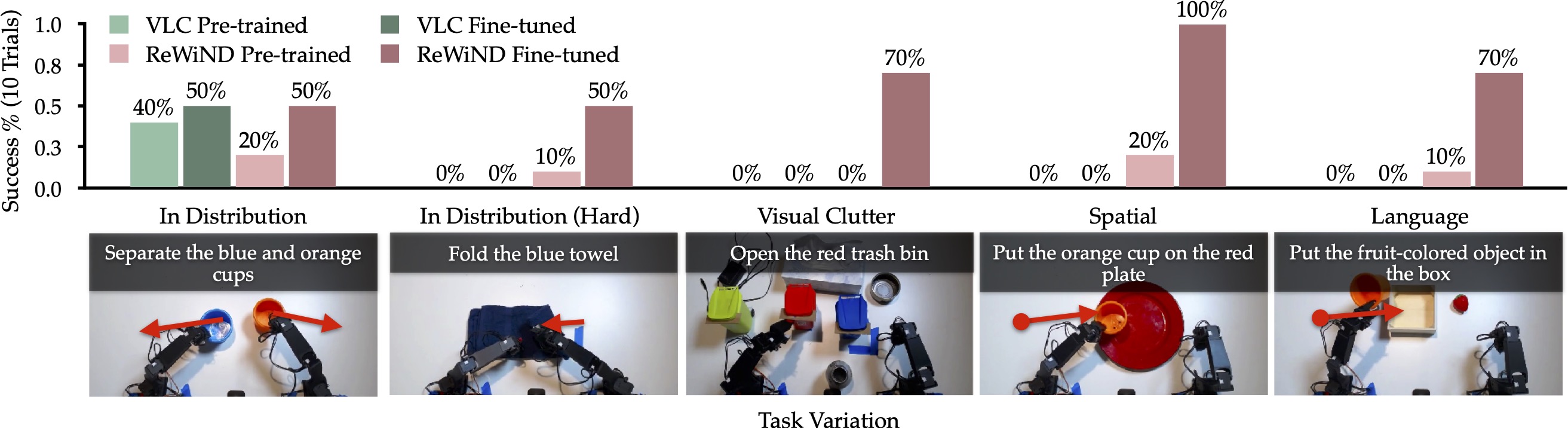
Policy Success Rate after fine-tune with ReWiND reward
Evaluation Rollouts
Reward Analysis
Below we evaluate the reward model's performance Qualitatively and Quantitatively.
Qualitative Reward Analysis
We qualitatively analyze the reward model's performance by examining how it rewards successful, partially successful, and a fully reversed demonstration from an unseen task.
MetaWorld Reward Alignment Videos
Successful Policy Rollout: ReWiND rewards increase from 0 to 1 as the task progresses successfully.
Partially Successful Policy Rollout: ReWiND rewards increase and then stay constant as the arm dithers back and forth near the button.
Failed Policy Rollout: ReWiND rewards decrease to 0 as the policy fails to complete the task.
Confusion Matrix
We evaluate reward confusion matrices on unseen tasks. The rows are videos of task demonstrations and the columns are language instructions. We expect the reward model to assign high rewards (blue color) to the diagonal matching elements and low rewards (white color) to the off-diagonal elements.


Quantitative Reward Analysis
We consider various metrics for analyzing reward models with offline videos and encourage looking at the paper for more details. We consider analyzing the reward models across three axes: (1) Demo Video Reward Alignment, (2) Policy Rollout Reward Ranking, and (3) Input Robustness. We find that ReWiND outperforms the baselines on all three axes, and ReWiND with Open-X data performs better than the one with only MetaWorld data on Robustness.

Improving with ReWiND
BibTeX
@inproceedings{
zhang2025rewind,
title={ReWi{ND}: Language-Guided Rewards Teach Robot Policies without New Demonstrations},
author={Jiahui Zhang and Yusen Luo and Abrar Anwar and Sumedh Anand Sontakke and Joseph J Lim and Jesse Thomason and Erdem Biyik and Jesse Zhang},
booktitle={9th Annual Conference on Robot Learning},
year={2025},
url={https://openreview.net/forum?id=XjjXLxfPou}
}